Data leakage
StandardScaler cannot leak target information
I keep encountering the advice that no preprocessing whatsoever should happen before a train/test split—not even something as harmless-seeming as standardizing the features.
According to this view, every transformation, including StandardScaler, must be fitted after partitioning the data to avoid leakage.
For example, Yuriy Guts argues for exactly this point in his nice talk at ODSC
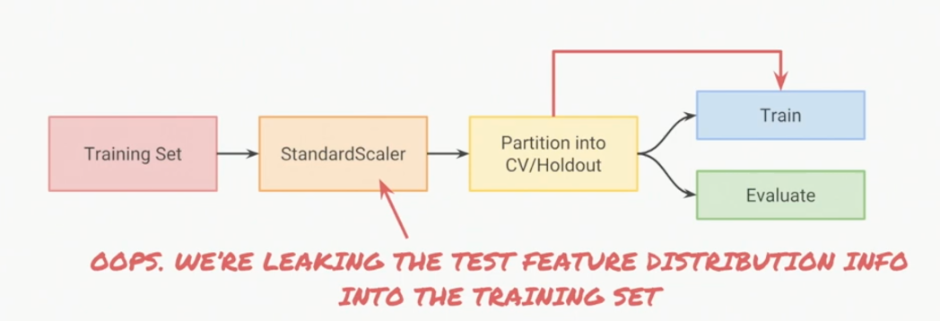
But is that really necessary? After all, standardization doesn’t look at the target variable at all. So should we truly worry about scaling before the split?
StandardScaler is safe
1. Not all preprocessing can cause leakage
Only preprocessing steps that use information derived from the target variable y or from relationships between X and y can leak information.
Examples of potentially leaky preprocessing:
- Imputing missing values using a method depending on
y - Using target encoding
- Feature selection based on correlation with
y - Scaling based on residuals, errors, model coefficients
- PCA applied to the full dataset when y is later predicted (subtle case)
These must be learned only from the training set.
2. It is wrong to claim that any preprocessing must be after splitting
There are two broad categories of preprocessing:
A. Transformations that depend on y: MUST avoid using test data.
These can leak. Agreed.
B. Transformations that depend only on X and do not encode structure tied to y:
No leakage whatsoever. Period.
This includes:
- StandardScaler
- MinMaxScaler
- RobustScaler
- PowerTransformer
- PCA (if unsupervised; but even this is debatable — see below)
- Simple log-transformations
- Converting strings to lowercase
- Removing punctuation
- Replacing outliers based on absolute thresholds
- Image resizing
- Audio normalization
- Tokenization (except supervised embeddings)
These transformations do not incorporate y, so they cannot “cheat.”
Scaling the entire dataset before splitting does not help the model peek at y.
3. The StandardScaler uses no information on y
Standard scaler does:
\[z = \frac{x-\mu}{\sigma}\]where $\mu$ and $\sigma$ are statistics of X only, not y.
There is no mechanism by which scaling the full dataset reveals anything about the target.
Scaling before splitting cannot cause overfitting
It might change the numerical values, but it cannot reduce test error by leaking y.
Pipelines
4. Then why do tutorials insist on pipelines?
Because:
1. In practice, you are rarely just scaling.
One day you add:
- feature selection
- imputers
- encoders
- customized preprocessing
- transformations based on correlations
Suddenly leakage is possible.
Pipelines protect you from future mistakes.
2. Cross-validation is the real reason.
If you scale the full dataset before CV:
- every fold sees statistics from the “future” folds
- this is technically leakage
- although for StandardScaler, the effect is zero!
This is the main reason people recommend:
“Always include preprocessing in the pipeline.”
Even if StandardScaler itself is harmless, CV logic requires consistent handling.
5. Why some instructors overstate the rule
Because they want students to adopt a simple, universal rule that prevents them from making accidental mistakes later.
The simple rule:
“Never preprocess before splitting.”
is safe, but not logically necessary for transformations that do not involve y.
It’s safe pedagogy, not accurate theory.
6. test-set-specific outliers
One counter argument often made is that
“test-set outliers can artificially improve test performance”
Let’s clarify:
✔️ What is not true:
- Scaling with test outliers does NOT help the model “cheat” on predicting y
- Scaling with test outliers does NOT reveal target information
- Scaling with test outliers does NOT reduce the fundamental prediction difficulty
So there is no leakage in the causal sense (no y is being smuggled in).
✔️ What is true (but subtle):
When test-set outliers influence the global mean/variance, the model will see a slightly rescaled test set.
This changes the numerical MSE slightly, but:
- it does NOT reduce overfitting
- it does NOT give information about the target
- it does NOT help the model “prepare” for y
- and the effect is usually statistically trivial
It is NOT data leakage by any accepted definition.
It’s best described as:
A tiny, harmless shift in the coordinate system, not a source of improper generalization.
If a blog or instructor claims outlier scaling is “leakage,” they are simply misusing the term.
Still not a reason to forbid scaling before splitting — but pipelines ensure reproducibility and fairness.
One-Hot Encoding and Leakage
One-hot encoding is often portrayed as something that must be done after the train/test split to prevent data leakage, but this is an oversimplification. OHE itself does not use the target variable and therefore does not introduce leakage in the classic sense. The real danger only appears when OHE is combined with y-aware methods like target encoding—or when category-level decisions, such as grouping rare categories or creating columns for categories that occur only in the test set, are influenced by information outside the training set. These are subtle issues of test-set contamination, not target leakage. In practice the effects are usually small, but using a pipeline keeps everything technically correct and reproducible.
Final verdict
-
Scaling the whole dataset before splitting does not leak information about y and does not cause overfitting.
-
The above state rule is pedagogically safe but technically incorrect.
-
Pipelines are still recommended
Not because StandardScaler leaks, but because:
- They avoid leakage for other steps
- They guarantee correct behavior in cross-validation
- They enforce a reproducible workflow